Ne vous fiez pas aux résultats d’un seul outil RAG
Comparez deux outils RAG à l’aveugle et évaluez leurs résultats
À quoi sert CompaRAG ?
CompaRAG est un outil gratuit qui permet de comparer objectivement les outils RAG et de découvrir leurs forces respectives.
Comparer les résultats de différents outils RAG
Soumettez la même tâche à deux outils et choisissez le meilleur résultat


Tester au même endroit les outils RAG de l’écosystème
Testez différents outils RAG, quel que soit leur fournisseur, sur vos propres cas d’usage.
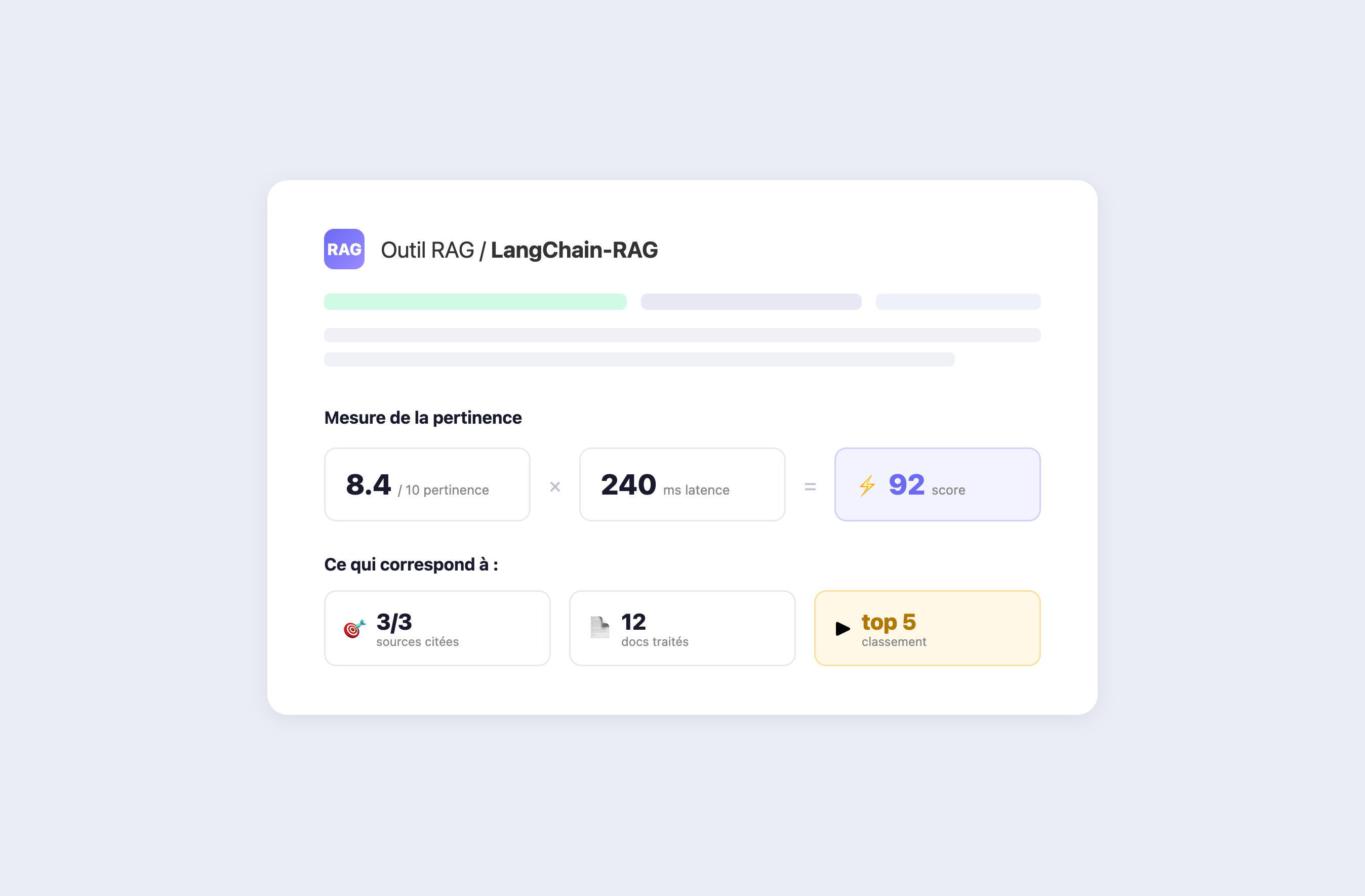
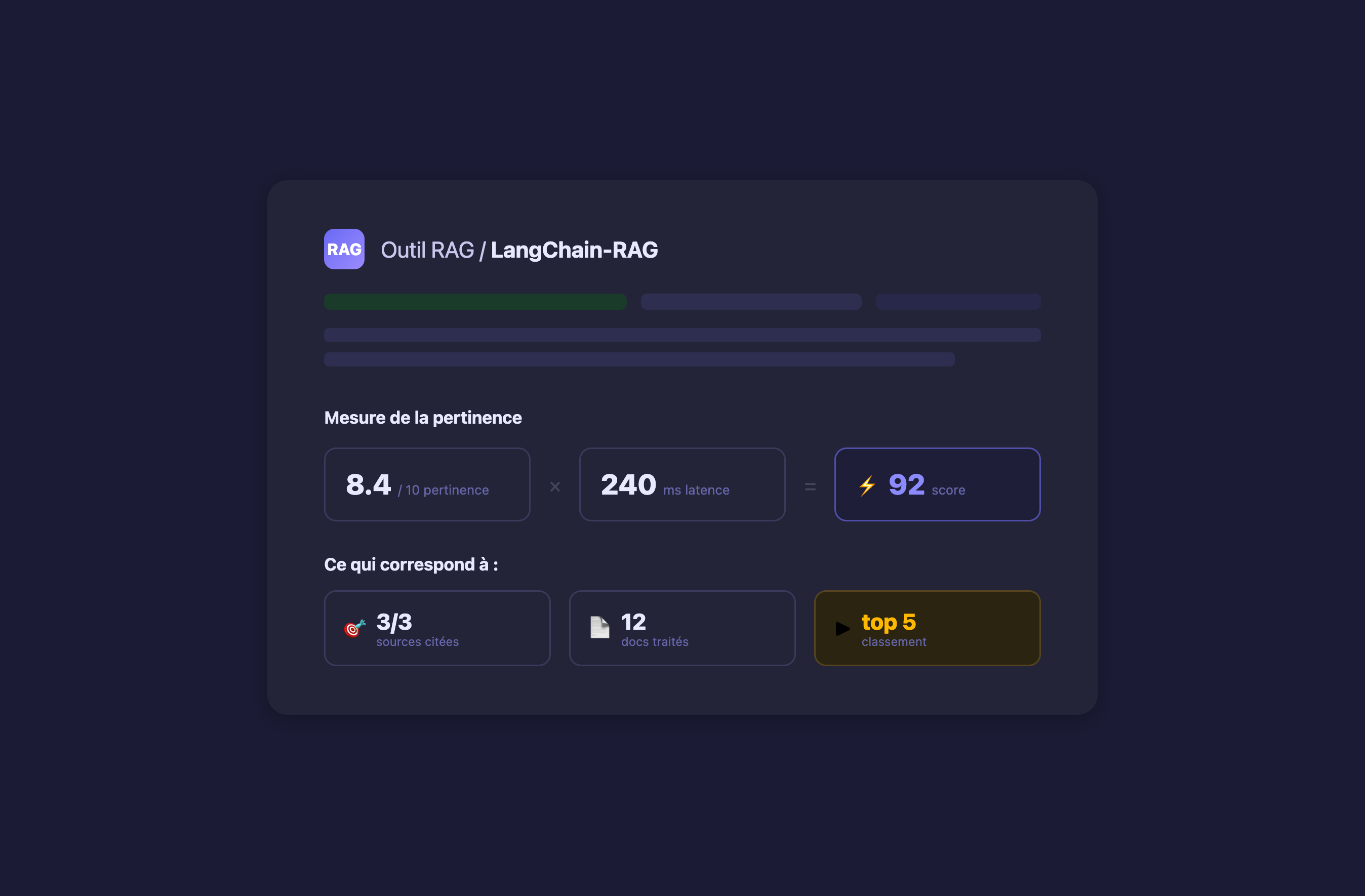
Mesurer la performance des outils sur vos cas d’usage
Découvrez quel outil répond le mieux à vos besoins métier
Pourquoi votre vote est-il important ?
Vos votes alimentent le classement public des outils RAG et un jeu de données ouvert que la communauté peut réutiliser pour entraîner et évaluer ses propres systèmes.

Vos préférences
Après avoir lu les deux réponses en aveugle, vous indiquez laquelle vous semble la plus pertinente. C'est le signal humain que les benchmarks automatiques manquent.

Un jeu de données ouvert
Toutes les comparaisons et les votes sont compilés dans un jeu de données publié librement sur Hugging Face, après anonymisation.

Des outils RAG améliorés
Chercheurs, équipes produit et auteurs d'outils RAG peuvent exploiter ces préférences humaines pour mesurer la qualité réelle de leur pipeline et l'améliorer là où ça compte.
Les usages spécifiques de CompaRAG
CompaRAG s'adresse aussi aux développeurs RAG, aux chercheurs et aux formateurs qui cherchent des données de comparaison concrètes sur des pipelines de récupération.
Exploiter les données
Développeurs, architectes, équipes produit… accédez aux données de comparaison CompaRAG pour évaluer les outils RAG sur vos propres critères.
Explorer les outils RAG
Consultez au même endroit les choix d'architecture (chunker, retriever, reranker) et les performances réelles de chaque outil.
Former et sensibiliser
Utilisez CompaRAG comme support pédagogique pour comparer les pipelines RAG et expliquer leurs différences à votre public.
Vos questions les plus courantes
Trois invariants garantissent l'équité de chaque manche.
1. Même contexte. Les deux outils reçoivent exactement la même question, le même document, et la même limite de temps. Le code qui construit la requête (backend/tool_arena/rag_tool/ask_one_tool.py) est unique : pas de chemin spécial par outil.
2. Tirage transparent. Seuls les outils déclarés READY au moment de la requête entrent dans le tirage. Ils sont groupés par task_type — résumé, question-réponse, extraction — et un outil n'affronte qu'un autre outil du même groupe (pas de QA contre Résumé). Au sein d'un groupe, deux outils sont pris au hasard, pondérés par un poids public déclaré dans mcp_servers.json.
3. Vote en aveugle. L'identité des deux outils est cachée jusqu'à votre vote. Vous voyez « réponse A » et « réponse B », pas leur marque. Toute mention de l'outil dans sa propre réponse est effacée avant affichage.
Le code de ces trois mécanismes est public et auditable : backend/tool_arena/comparison/ask_two_tools_concurrently.py, backend/tool_arena/rag_tool/readiness.py, backend/tool_arena/blind_reveal/hide_tool_identity_before_vote.py.
Quatre étapes, dans l'ordre :
- Tirage de deux RAGTool prêts (cf. question sur l'équité).
- Interrogation parallèle : la même question et le document sont envoyés simultanément aux deux outils via MCP. Time-out individuel de 180 s.
- Aveuglement : chaque réponse est nettoyée pour effacer le nom de l'outil, puis affichée sans étiquette comme « réponse A » / « réponse B ». L'ordre est tiré au sort.
- Révélation : après votre vote, les deux identités s'affichent et le vote est enregistré.
Si l'un des deux outils tombe en erreur, vous voyez une carte d'erreur à sa place et le vote est désactivé — comparer une réponse à un échec n'a pas de sens.
« RAG » (Retrieval-Augmented Generation) désigne une catégorie d'outils qui combinent récupération d'information et génération par LLM. La même catégorie cache pourtant des choix d'architecture très différents :
- Quel chunker ? Découpage par paragraphe, par fenêtre de caractères, par phrase…
- Quel retriever ? Dense (embeddings), creux (BM25), hybride, graph-based (LightRAG, GraphRAG)…
- Quel reranker ? Cross-encoder, LLM-judge, ou rien.
- Quel prompt ? La même question peut donner des sorties radicalement différentes selon le prompt qui enrobe les passages retrouvés.
CompaRAG met aujourd'hui en compétition cinq familles de moteurs (LangChain, LlamaIndex, Haystack, Txtai, Chroma) sur le même LLM (Mistral Medium 3.1 via OpenRouter). La constante du LLM est volontaire : on mesure la qualité du pipeline de récupération, pas la qualité du modèle final.
Vos questions et vos votes sont publiés en jeu de données ouvert sur Hugging Face (comparag-tool-votes) après filtrage des informations personnelles. C'est l'objet du projet : produire un corpus public de préférences humaines entre outils RAG, utilisable pour entraîner et évaluer d'autres systèmes.
Les documents que vous uploadez ne sont pas publiés. Ils sont passés aux deux outils RAG pour leur permettre de répondre, puis effacés du cache à la fin de la session (24 h).
Vous pouvez demander la suppression d'un vote précis en nous contactant — le vote est alors archivé et exclu du prochain export du dataset.
L'arène est faite pour grossir. Cinq étapes, environ trente minutes :
- Copier le template
mcp_servers/_template_new_tool/. - Remplir
tool.manifest.yaml(nom, but, transport, port, task_type). - Implémenter la fonction
rag_query(task, goal, document_content)deserver.pyavec la logique de votre outil. - Lancer
python scripts/register_tool.py <slug>: la commande met à jourmcp_servers.jsonet l'ontologie automatiquement. - Vérifier
pytest backend/etpython scripts/check_openrouter_providers.py.
Guide complet : docs/add_a_new_rag_tool.md. Liste de candidats à intégrer : LightRAG, R2R, Vectara MCP, PaperQA2, Verba, RAGFlow, Cohere RAG, Pinecone MCP.